


Reducing warranty costs of Valtra's tractors with Machine Learning
Computationally more powerful edge devices have enabled a new way of performing Machine Learning and Artificial Intelligence - Edge AI. Where does the need for Edge AI come from and how does it actually work?
In a typical machine learning setting, we first start by training a model for a specific task on a suitable dataset. Training the model essentially means that it is programmed to find patterns in the training dataset and then evaluated on a test dataset to validate its performance on other unseen datasets, which should have similar properties to the ones that the model is trained on.
Once the model is trained, it is deployed or "put to production", meaning that it can be used for inference in a specific context, for example as a microservice. The model works via an API, and its endpoint(s) are queried for predictions by pinging them with input data. The model output is then either communicated to another software component or in some cases displayed on the application frontend.
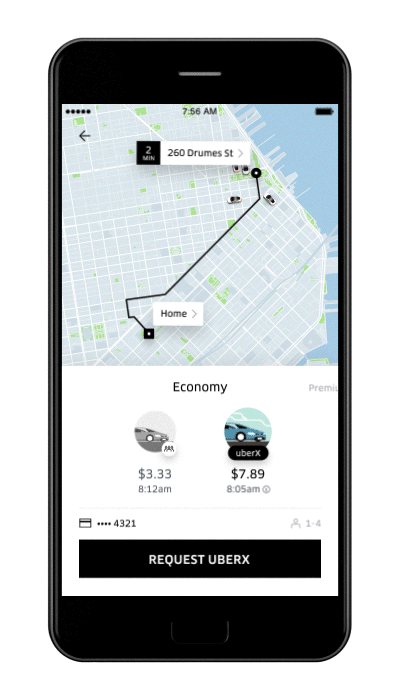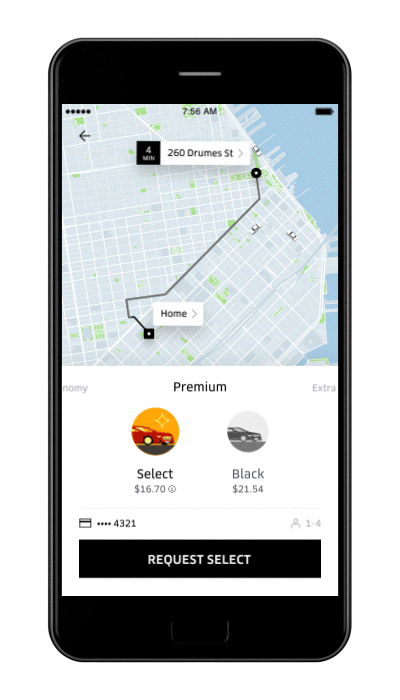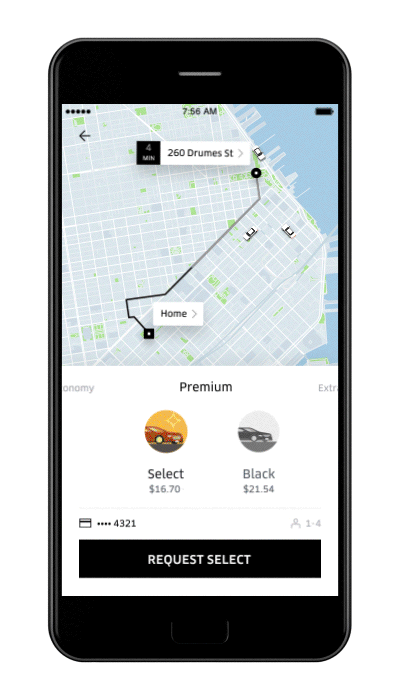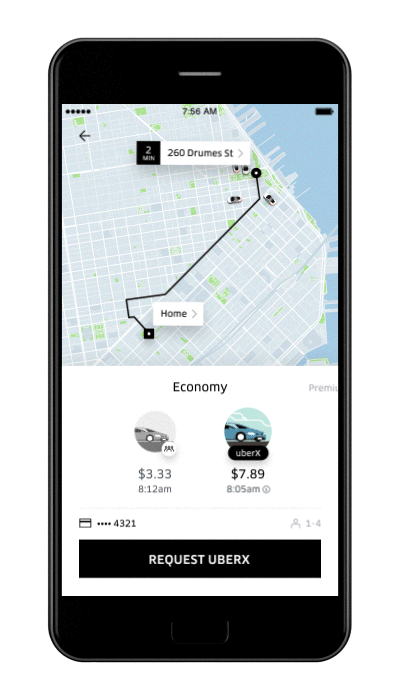 Example: As a ride is requested, the Uber app displays the predicted pickup time to the customer on the app frontend.
Example: As a ride is requested, the Uber app displays the predicted pickup time to the customer on the app frontend.
The rise of cheap computing and data storage resources with cloud infrastructure has given newfound opportunities to leverage machine learning at scale. However, this comes at the cost of latency and data transfer challenges due to bandwidth limitations.
Training a machine learning model is a computationally expensive task well suited for cloud-based environment, whereas inference requires relatively low computing resources. However, with inference, one of the most important factors is latency.
Given the new trends of Industry 4.0, autonomous systems and intelligent IoT devices, the old paradigm of executing inference in cloud is starting to get increasingly less suitable as needs for real-time predictions grow.
If a machine learning model lives in the cloud, we first need to transfer the required data (inputs) from the end-device, which it then uses to predict the outputs. This requires a reliable connection and given that the amount of data is large, the transfer can be slow or in some cases impossible. If the data transfer fails, the model is useless.
In the case of successful data transfer, we still need to deal with latency. The model naturally has some inference time, but the predictions also need to be communicated back to the end-device. It's not hard to imagine, that in mission-critical applications, where low latency is essential this type of approach fails.
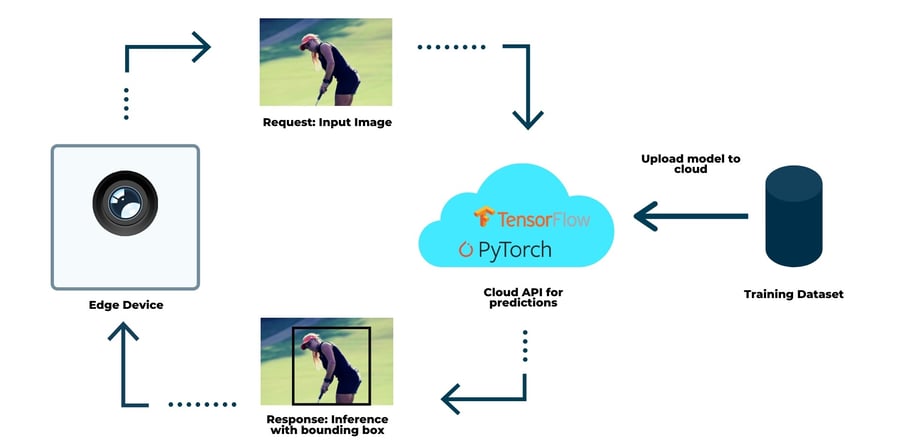
The cloud architecture for Inference
Computationally more powerful edge devices have enabled a new way of performing machine learning and artificial intelligence - Edge AI.
Contrary to the traditional setting, where the inference is executed in a cloud computing platform, with Edge AI the model works in the edge device without requiring connection to the outside world at all times.
The process of training a model on a consolidated dataset and then deploying it to production is still similar to cloud computing though. This approach can be problematic with edge devices for multiple reasons.
First, it requires building a dataset by transferring the data from the devices to a cloud database. This is naturally problematic due to bandwidth limitations. Second, the data cannot be considered even remotely independent and identically distributed as it is hierarchically clustered by device and most likely asymmetrical. In practice, this means that data from one device can not be used to predict outcomes from other devices reliably.
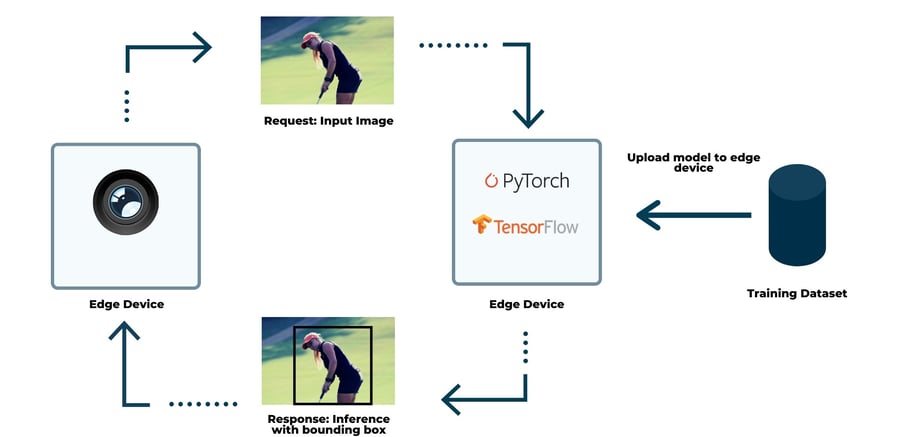
Edge based architecture - inference happens locally on a device
Finally, collecting and storing a centralized dataset is tricky from privacy perspective. Limitations imposed by legislations such as GDPR are creating significant barriers to training machine learning models. Moreover, the centralized database is a lucrative target for attackers. Therefore, the popular statement that edge computing alone answers to privacy concerns is false.
For tackling the above problems, federated learning is a viable solution.
Federated learning is a method for training a machine learning model on multiple client devices without having access to the data itself. The models are trained locally on the devices and only the model updates are sent back to the central server, which then aggregates the updates and sends the updated model back to the client devices. This allows for hyper-personalization while preserving privacy.
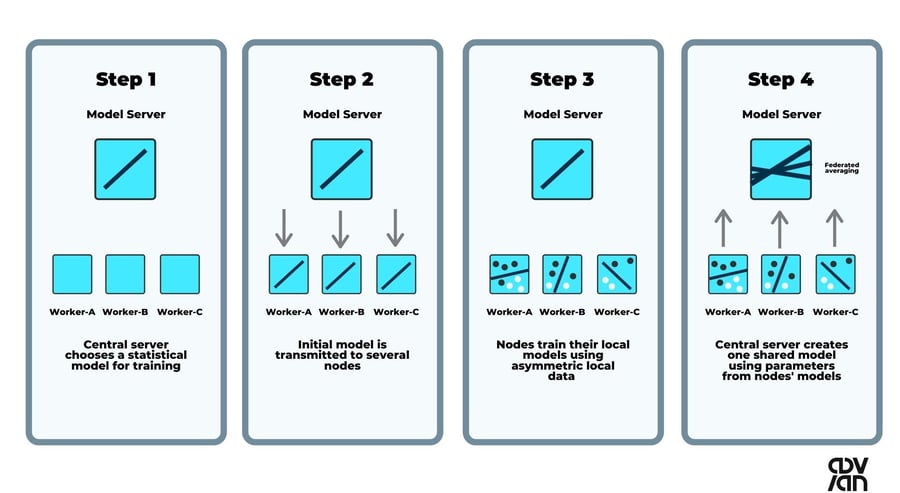
Federated learning process described
Edge computing is not going to entirely replace cloud computing, rather it's going to work in conjunction with it. There are still multiple applications, where cloud-based machine learning performs better, and with vanilla Edge AI the models still need to be trained in cloud-based environments.
In general, if the applications are tolerant to cloud-based latencies or if the inference can be executed directly in the cloud, cloud computing is a better option. However, with applications that require real-time inference "on the edge" and have poor connectivity or high latency, edge computing is the only feasible solution.
Further reading
https://www.udacity.com/course/intel-edge-ai-for-iot-developers-nanodegree--nd131

Wonder what you could achieve
with Edge AI?
Book a meeting with our expert below 👇


