

Reducing warranty costs of Valtra's tractors with Machine Learning
Do you ever wonder how the texting app on your mobile phone can predict the next word you're about to type? The app is often eerily precise on guessing your next thought. If you figured there's some black arts at play, you were right. The app's intelligence comes from the 21st century sorcery, also known as machine learning.
The next obvious question is where the data for training the model comes from. Do you generate enough data by yourself to make the model intelligent or are your private messages shared with millions of other users? The answer to both questions is "no".
So, before you start googling the instructions on how to fold a tinfoil hat or building an apartment-wide Faraday cage, read on. The prediction model for the texting app, at least if you're using Android or iOS, is trained using a technique called federated learning, which enables mobile phones to collaboratively learn a shared prediction model while keeping all the training data on device.
When you go home at night and your phone connects to Wi-Fi, occasionally, the app does some local training on the device using your data. It then sends the slightly smarter model to the central server, and after a while you get back an updated aggregation of everyone else's models. The benefit in this approach is that you can enjoy a smarter model on the phone - even though you're not generating enough training data for the model to become intelligent. Also, none of the private data needs to be shared.
On a high level, federated learning consists of four distinct steps.
The steps that occur sequentially are often referred to as “round”. The figure below illustrates a Single Party system, where one entity is responsible for governing the shared model.
Step 1: A generic baseline model is trained on a central server.
Step 2: The model is sent to the client devices.
Step 3: The local copies of the model are then improved by training them using the client-specific data. Usually, these data points are unique to the device or user.
Step 4: The model updates, i.e. the learned parameters or gradients, are periodically sent to the central server. Finally, the central server creates an aggregation of the learned parameters and shares them with the clients.
The process is then repeated to further improve the shared model.
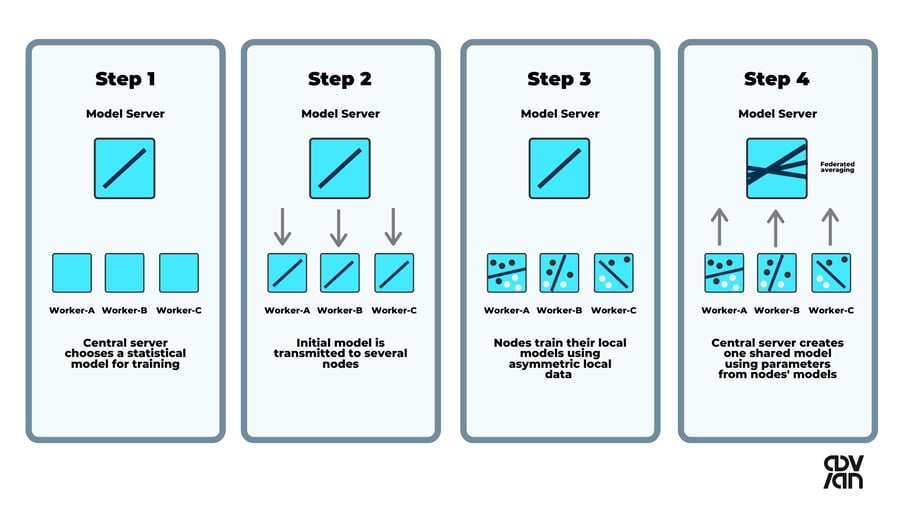
Federated learning process described (adapted from Comparitech's example)
What is the difference between federated learning and centralized machine learning?
Federated learning, to put it shortly, is a way to train machine learning models on data which you do not have access to. It brings the models to the data source instead of bringing the data to the model, as opposed to the traditional machine learning setting, where a model is trained on a consolidated set of training data, often stored on a cloud-based computing platform.
Generally, the term machine learning refers to computer algorithms that can carry out computations without the programmer having to explicitly define them. The program can "learn" patterns from data and generalize them to new unseen data.
This traditional way of machine learning, "centralized machine learning", involves the process of first consolidating the data to a centralized database before being able to make predictions. Several limitations arise due to this approach, most notable of them relating to privacy - especially in the case of personal user data.
Tackling privacy concerns
Storing massive amounts of user data on a central database is a dubious practice on its own, but this data is also susceptible to hacking and data leaks. The more personal the data is, the bigger the risks. To make things more difficult for machine learning development, governments in multiple countries have taken action to protect the privacy of their citizens with strict measures such GDPR. Due to the legal limitations, development of ML applications has been hindered and, in some cases, become impossible.
Even after "anonymizing" a dataset, the private data can be divulged by exploiting another related dataset and combining the information from the two separate datasets. A recent example is the "Netflix Prize" dataset, which was part of the competition, where Netflix set out to find a recommendation algorithm using data from half a million users. The usernames and the movie titles were replaced with unique integer ids in the dataset.
Although the real names of the people nor the movie names were released, two researchers were able to de-anonymize both the names of the movies and the names of the individuals by comparing which users rate movies both on IMdB and Netflix.
Applications
Federated learning applications have multiple highly potential use cases from healthcare to edge analytics. Most promisingly they answer to situations, where user privacy and algorithm development are not aligned, or data cannot be effectively transferred.
Predictive keyboard with Google Gboard
Google has already implemented federated learning in a large-scale application, Gboard. Developing a keyboard application by storing all the user messages to a centralized database would’ve been extremely obtrusive and likely caused more harm than good. With this problem at hand, Google pioneered the approach of developing a machine learning model without having access to any of the training data.
With Google’s solution, the model learns locally the words that the user is likely to type. It then summarizes the relevant information regarding the user profile and sends a summarized update to the global model. Similar users can be grouped together and once the improved shared model is pushed back to users, they can enjoy better keyboard suggestions.
Physical activity optimization with wearable devices
Wearable devices, such as activity trackers, offer a great way to track one's living habits as well as heart rates and sleep cycles, but currently they contain little intelligence. Personal bio-metric data is very sensitive, and even as it already resides in the device manufacturers' clouds, using it to create machine learning algorithms is tricky. Additionally, a wearable device user does not create enough data on their own to train an intelligent model.
In this context, federated learning can offer 3rd party companies a privacy-preserving solution to optimize the users’ living habits such as optimal daily activity level to achieve best sleep quality. No data needs to be transferred to a 3rd party cloud storage and the users can benefit from data collected from users with close to similar profiles.
In addition, federated learning allows for hyper-personalization instead of a sub-optimal global model, which performs poorly on user level.
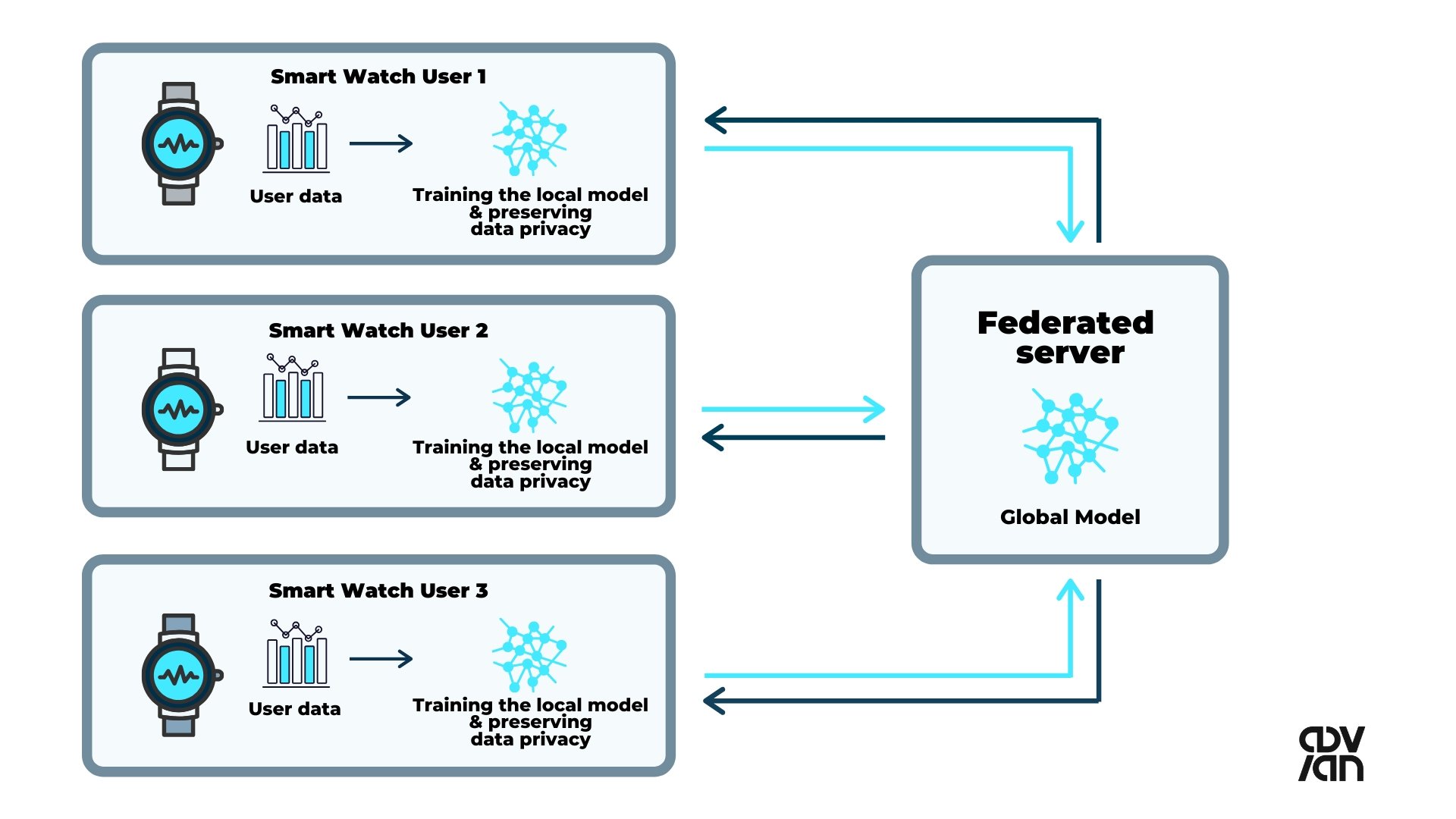
A centralized-server approach to federated learning (adapted from NVIDIA's example).
Federated learning challenges
While federated learning aims to preserve privacy, there are security issues that should still be noted. One of the most prominent issues from machine learning perspective is model poisoning, which refers to a malicious actor corrupting the model and changing its behavior to suit their agenda.
As described by researchers from Cornell University, the attackers can potentially take over one or more clients and alter how the model is trained locally - for example hyper parameters or the weighting of the individual model. This way the attackers can backdoor and modify the shared model and change its behavior. In the paper, it was demonstrated that poisoning the federated learning model was significantly more effective than poisoning the data.
Bonawitz and his research group discuss the technical limitations and potential bias that might affect feasibility and performance of the federated learning. The bandwidth limits and the availability of unmetered networks will affect how the models can be trained locally. The device bandwidths haven’t grown at the same pace with computing power, and insufficient network bandwidth can reduce the model convergence time.
Another aspect is potential bias that is introduced by dropping out devices that are not within an unmetered network or don’t possess enough processing power for model training. Due to the bias, the shared model might not turn out as accurate as possible.
Federated learning future
In addition to ensuring privacy, federated learning allows for smarter, more personalized models, lower latency and in some cases better algorithmic performance as described by Nilsson et al. Besides updating the shared model, the improved individual model can be used immediately powering dynamic, real-time predictions often required in edge analytics.
Federated learning is still in its nascent stages, but it already shows promise in wide array of different applications. However, to utilize the power of federated learning, machine learning practitioners need to adapt to a new paradigm in the whole life cycle of the model building - with no direct access to raw data and the cost of communication as a limiting factor. Given the benefits that come with federated learning, the technical challenges should be worthwhile to tackle.
Further reading
https://www.udacity.com/course/secure-and-private-ai--ud185
https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
https://hackernoon.com/a-beginners-guide-to-federated-learning-b29e29ba65cf
https://www.amazon.com/Federated-Learning-Synthesis-Artificial-Intelligence/dp/1681736977
Popular frameworks for Python
https://github.com/OpenMined/PySyft
https://www.tensorflow.org/federated
https://github.com/FederatedAI/FATE

Need help with your data and analytics challenges?
Book a meeting with our expert below 👇


